The 7 Steps of Machine Learning
피부암 진단에서부터 오이분류, 수리가 필요한 에스컬레이터 판별까지 머신러닝은 컴퓨터시스템에 완전히 새로운 능력을 부여하였다.

그러면 머신러닝은 실제 내부적으로 어떻게 동작할까? 기본적인 예제로 살펴보고 이를 머신러닝을 사용하여 데이터에서 해답을 얻는 절차에 대한 이야기거리로 사용한다.
음료가 와인인지 맥주인지에 대한 질문에 답하는 시스템을 만들어야 한다고 해보자. 우리가 만드는 질문에 대답하는 시스템을 "모델(model)"이라고 하고 이 모델은 "훈련(training)"이라는 절차를 통해 만들어진다. 훈련의 목표는 대부분의 경우 우리의 질문에 올바르게 대답하는 정확한 모델을 만드는 것이다. 그러나 모델을 훈련하려면 훈련하기 위한 데이터를 수집해야 한다. 여기가 우리가 시작하는 곳이다.
This is just the beginning
Wine or Beer?
우리의 데이터는 와인잔과 맥주잔에서 수집될 것이다. 우리가 데이터를 수집할 수 있는 음료의 많은 측면 즉, , 거품의 총량에서 잔의 모양까지가 있다.

우리의 목표를 위해 우리는 색상(파장의 길이)과 알콜 함량(백분율로)의 두가지 샘플만을 선택한다. 이 두가지 요인으로 두가지 음료를 구분할 수 있다는 희망이 있다. 이제부터는 이 두가지 요인을 색상(color)와 알콜(alchol) "특성(feature)"라고 한다.
절차의 첫번째는 가게로 달려가서 다수의 다른 맥주와 와인과 몇몇 측정을 하기위한 기구을 사는 것일 것이다. - 색상을 측정하기 위한 스펙트럼 측정기, 알콜함량을 측정하기 위한 비중계.
Gathering Data
장비와 술을 확보하면 머신러닝의 진짜 첫번째 단계인 데이터 수집(gathering data)이다. 이 단계는 수집하는 데이터의 질과 양이 여러분의 예측 모델이 얼마나 훌륭해질 수 있는지 직접적으로 결정할 수 있기 때문에 중요하다. 이번 경우에는 우리가 수집하는 데이터가 각 음표의 색상과 알콜함량이 될 것이다.

수집된 데이터는 색상, 알콜함량 그리고 맥주인지 와인인제에 대한 표를 만들 것이고 이 것이 훈련 데이터(training data)가 될 것이다.
Data preparation
훈련 데이터가 수집되면 이제는 머신러닝의 다음 단계인 데이터 준비(data preparation)단계이다. 여기서 데이터를 적절한 공간에 로드하고 머신러닝 훈련에 사용하기 위해 이를 준비한다.
우선 모든 데이터를 함께 모으고 순서를 무작위로 섞는다. 순서는 음료가 맥주인지 와인인지 결정하는 부분이 아니기때문에 데이터의 순서가 학습하는 것에 영향을 미치지 않아야 한다. 즉, 음료가 무엇인지 결정하는 것은 어떤 음료가 앞에 또는 뒤에 있었는지에 대해 독립적이다.

이 단계는 또한 이익이 될 수 있는 다른 변수간 어떤 관계가 있는지 또한 어떤 데이터가 불균형(inbalance)한지를 볼 수 있도록 여러분의 데이터에 대해 적절한 시각화를 하기에도 좋은 단계이다. 예를 들면, 만약 와인보다 맥주에 대해 더 많은 데이터 포인트가 수집되었다면 우리가 훈련하는 모델은 대부분 맥주가 올바른 구분이기 때문에 모델이 예측하려는 사실상 모든것이 맥주라는 편향된 추측을 할 것이다. 그러나 실제로는 모델은 동일한 양의 맥주와 와인을 볼 것이다. 이는 맥주를 예측하는 것이 절반은 틀릴 것이라는 의미이다.
또한 데이터를 두 부분으로 나눌 필요가 있다. 모델 훈련을 위해 사용되는 첫번째 부분은 데이터셋의 대부분이 포함된다. 두번째 부분은 훈련된 모델의 성능을 평가하기 위해 사용된다. 수학시험에서 숙제로 나왔던 동일한 문제를 사용하지 않는 것처럼 훈련과 평가에 동일한 데이터를 사용하면 단지 "질문(question)"을 기억할 뿐이게 되므로 모델 훈련에 사용된 동일한 데이터를 평가에 사용하지 않는다.
때때로 수집된 데이터는 조정과 곱셈의 다른 형태가 필요하다. de-duping(동일한 데이터 제거), normalization(정규화), error correction(오류 수정) 등과 같은 것들이다. 이것들은 데이터 준비단계에서 모두 나타날 수 잇다. 우리의 경우 추가적인 데이터 준비는 필요하지 않다.
Choosing a model
작업흐름에서 다음 단계는 모델 선택(Choosing a model)이다. 연구자와 데이터 과학자가 수년동안 만든 많은 모델이 있다. 몇몇은 이미지 데이터에 아주 적합하고 몇몇은 시퀀스(text나 음악같은), 몇몇은 수치 데치터에, 또다른 몇몇은 텍스트기반 데이터에 아주 적합하다. 우리의 경우 단지 2가지 특성, 색상과 알콜함량만 있기 때문에 소규모 선형 모델을 사용할 수 있다. 이 모델은 작업을 완료할 수 있는 꽤 간단한 모델이다.
Training
이제 종종 머신러닝의 대부분으로 여겨지는 훈련(training)단계이다. 이 단계에서 주어진 음료가 와인인지 맥주인지 예측하기 위한 모델의 능력을 점진적으로 개선하기 위해 데이터를 사용한다.

어떤면에서 운전을 처음 배우는 누군가와 비슷하다. 처음에는 페달, 노브(knobs), 스위치가 어떻게 동작하는지 그리고 언제 사용해야 하는지도 모른다. 그러나 많은 연습 그리고 실수를 바로잡은 후에 운전면허가 나온다. 게다가 몇년 후에는 꽤 능숙해진다. 운전하는 행위와 실생활 데이터에 반응하는 것이 운전능력을 맞추고 기술을 연마한다.

우리는 이러한 것을 음로로 훨씬 더 작은 규모에서 진행한다. 실제로 직선에 대한 식은 $y = mx + b$이다. 여기서 x는 입력, m은 직선의 기울기, b는 y-절편(intercept)이고 y는 위치 x에서 직선의 값이다. 조정 또는 "훈련"을 위해 사용가능한 값은 m과 b이다. 이 두 변수를 제외한 다른 변수는 오직 입력인 x와 출력인 y만 있기 때문에 직선의 위치에 영향을 줄 수 있는 다른 방법은 없다.

머신러닝에서는 많은 특성이 있을 수 있기 때문에 많은 m이 있다.이 m값들의 집합(collection)은 보통 행렬(matrix), W로 표시하는 "가중치(weights)"를 위한,로 만들어진다. b에 대해서도 유사하게 함께 모아 정렬하고 "편향(bias)"라고 한다.
훈련절차는 W와 b에 대해 몇몇 무작위 값을 초기화하고 이들 값으로 출력을 예측하는 것이 포함된다. 상상한것처럼 이는 꽤 신통치 않다. 그러나 모델의 예측과 예측해야만하는 출력을 비교하고 W와 b에서 값을 조정할 수 있다. 그렇게 좀 더 정확한 예측을 할 수 있다.

이 절차를 반복한다. 가중치와 편향을 갱신하는 각 반복(iteration) 또는 싸이클(cycle)을 하나의 훈련 "단계(step)"라고 한다.
이 경우 그 의미가 무엇인지 좀더 구체적으로 보자. 우리의 데이터셋에서 처음 훈련을 시작하면 데이터를 지나는 무작위 직선을 그린것 같다. 훈련 절차의 각 단계에서 단계적으로 직선이 와인과 맥주의 이상적인 구분에 더 가깝게 움직인다.
Evaluation
훈련이 완료되면 평가(evaluation)를 하여 모델이 좋은지를 본다. 이 단계가 앞서 따로 떼어놓은 데이터셋을 적용하기 시작하는 곳이다. 평가는 훈련에 사용된적 없는 데이터로 모델을 훈련한다. 이 지표(metric)는 모델이 본 적없는 데이터에 대해 얼마나 동작하는지를 보여준다. 이는 실제로 모델이 얼마나 동작할지를 나타낸다.
보통 경험적으로 훈련-평가 비율은 80/20 또는 70/30을 사용한다. 이것의 대부분은 원본 데이터셋의 크기에 따라 달라진다. 여러분이 많은 데이터를 확보했다면 아마도 평가 데이터셋에 큰 비중을 두지 않을 것이다.
Parameter Tuning
평가를 완료한 후 어떤 방법으로 추가적으로 훈련을 개선할 수 있는지를 알 수 있다. 파라미터 튜닝(tuning prameters)로 가능하다. 훈련시 암묵적으로 추정된 몇가지 파리미터가 있었고 지금 단계는 되돌아가 이들 추정을 테스트하고 다른 값으로 시도해보기 좋은 단계이다.
한가지 예로 훈련동안 훈련 데이터셋으로 얼마나 많이 훈련하였는가이다. 이것의 의미는 단지 한번보다 전체 데이터셋인 모델을 여러번 보여줄 수 있는 것이다. 이는 종좋 더 높은 정확도로 이어진다.
즉, 훈련 회수(epoch)

또다른 파라미터는 "학습률(learning rate)"이다. 학습률은 이전 훈련단계의 정보로 매 단계 직성을 얼마나 움직이는지를 정의한다. 이 값들은 모델이 얼마나 정확해 질 수 있는지 그리고 훈련이 얼마나 오래걸릴지에 대한 역할을 수행한다.
좀 더 복잡한 모델에 대해 초기 조건은 훈련의 결과를 결정하는데 중요한 역할을 수행할 수 있다. 0으로 초기화된 값으로 훈련을 시작한 모델과 몇몇 값의 분포로 초기화된 값으로 시작하는 모델에 따라 차이 있을 수 있다. 이는 어떤 분포를 사용해야하는가에 대한 물음으로 이어진다.
The potentially long journey of parameter tuning
훈련에 대한 이 단계에서 많은 조건이 있고 "충분히 좋은" 모델을 만드는 것을 정의하는 것이 중요하다. 그렇지 않으면 자신이 오랜시간동안 파라미터는 수정하고 있는 자신을 발견할 것이다.
이들 파라미터는 보통 "hyperparameters"로 나타낸다. 하이퍼파라미터의 조절 또는 튜닝은 약간의 예술로서 남는다. 그리고 여러분의 데이터셋, 모델 그리고 훈련 절차에 강하게 영향을 받는 실험적 절차에 더 가깝다.
훈련과 하이퍼파라미터, 가이드된 평가 단계에 만족하면 마지막으로 모델을 유용한 무엇인가를 하기 위해 사용할 시간이다.
Prediction
머신러닝은 데이터를 사용하여 질문에 답하는 것이다. 따라서 예측(Prediction) 또는 추론(inference)는 어떠한 질문에 대답을 얻는 것이다. 이것이 모든 작업의 핵심이다. 여기에서 머신러닝 값이 실현된다.

최종적으로 음료의 색과 알콜함량이 주어지면 음료가 와인인지 맥주인지 예측하느 모델을 사용할 수 있다.
The big picture
머신러닝의 힘은 사람의 판단과 수작업 규칙을 사용하는 것 대신, 모델을 사용하여 와인과 맥주를 구별하는 법을 결정할 수 있다는 것이다. 여러분은 부가적으로 다른 문제 분야에 오늘 설명된 아이디어를 추정할 수 있다. 다음의 동일한 이론이 적용된다.
- Gathering data
- Preparing that data
- Choosing a model
- Training
- Evaluation
- Hyperparameter tuning
- Prediction.
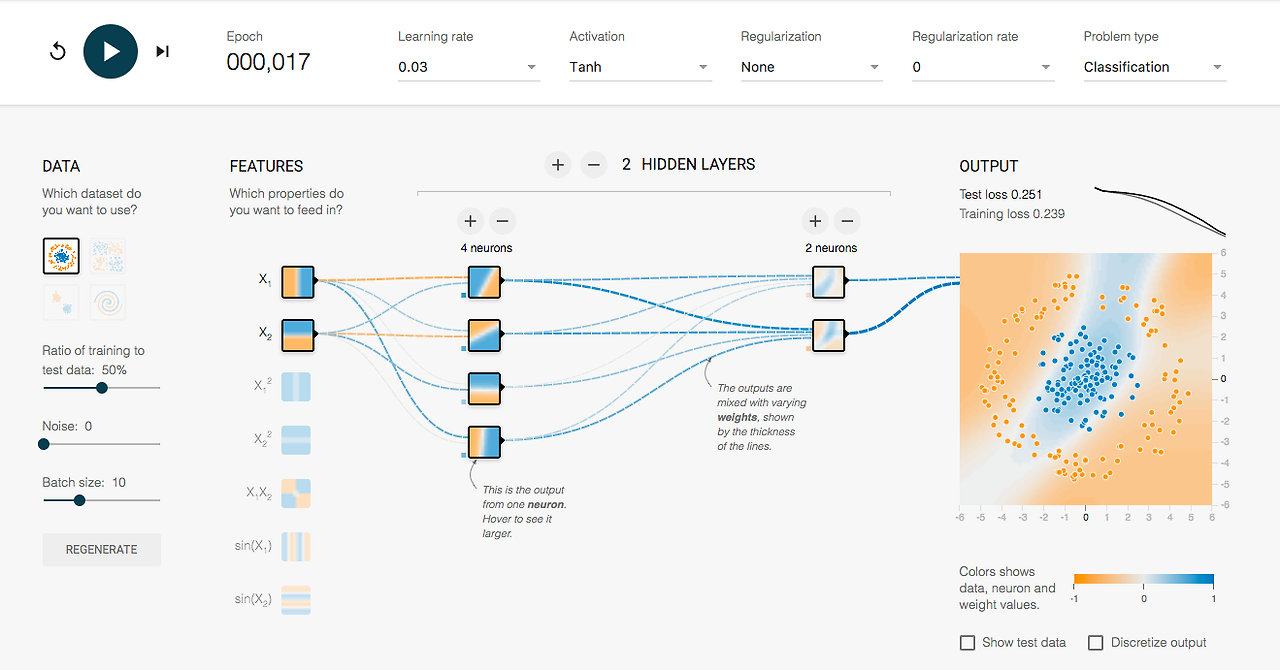
TensorFlow Playground
훈련과 파라미터를 다루기 위한 더 많은 방법은 TensorFlow Playground를 확인하는 것이다. 텐서플로우 플레이그라운드는 완전한 브라우져기반 머신러닝 샌드박스이다. 여기서 모의 데이터셋으로 다른 파라미터와 훈련을 해 볼 수 있다.