Visualize your data with Facets
데이터는 지저분하다. 종종 불균형(unbalanced)하고 레이블이 없으며 형편없게 값이 뿌려져 분석과 머신러능 훈련을 방해한다.
정리된 데이터를 얻기 위한 첫번째 단계는 정리가 필요한 곳을 이해하는 것이다. 이 글에서는 이 작업을 위한 도구를 소개한다.
Visualize your Data
데이터를 이해하는 것은 머신러닝을 위해 정리된 데이터셋을 얻기 위한 첫번째 단계이다. 그러나 어떠한 일반화된 방법으로 수행하기에 힘들 수 있다.
Facets라는 Google Research 오픈소스 프로젝트는 데이터를 시각화하여 모든 방법으로 이를 쪼갤 수 있다. 이는 데이터셋이 어떻게 배치되었는지를 알 수 있게 한다.
데이터가 기대하는 방법으로 보이지 않는 곳을 찾을 수 있게하여 Facets는 작은 사고를 줄이는데 도움을 준다.
Facets가 무엇처럼 보이는지 보자. 여러분이 설치없이 크롬브라우져에서 Facets를 해 볼 수 있도록 demo page on the web가 있다. 게다가 Facets 시각화는 Typescript code로 Polymer Web Components backed를 사용하여 쉽게 Jupyter와 웹페이지에 임베딩 될 수 있다.
Facets Overview
Facets overview는 여러분의 데이터셋에 대한 overview를 제공한다.
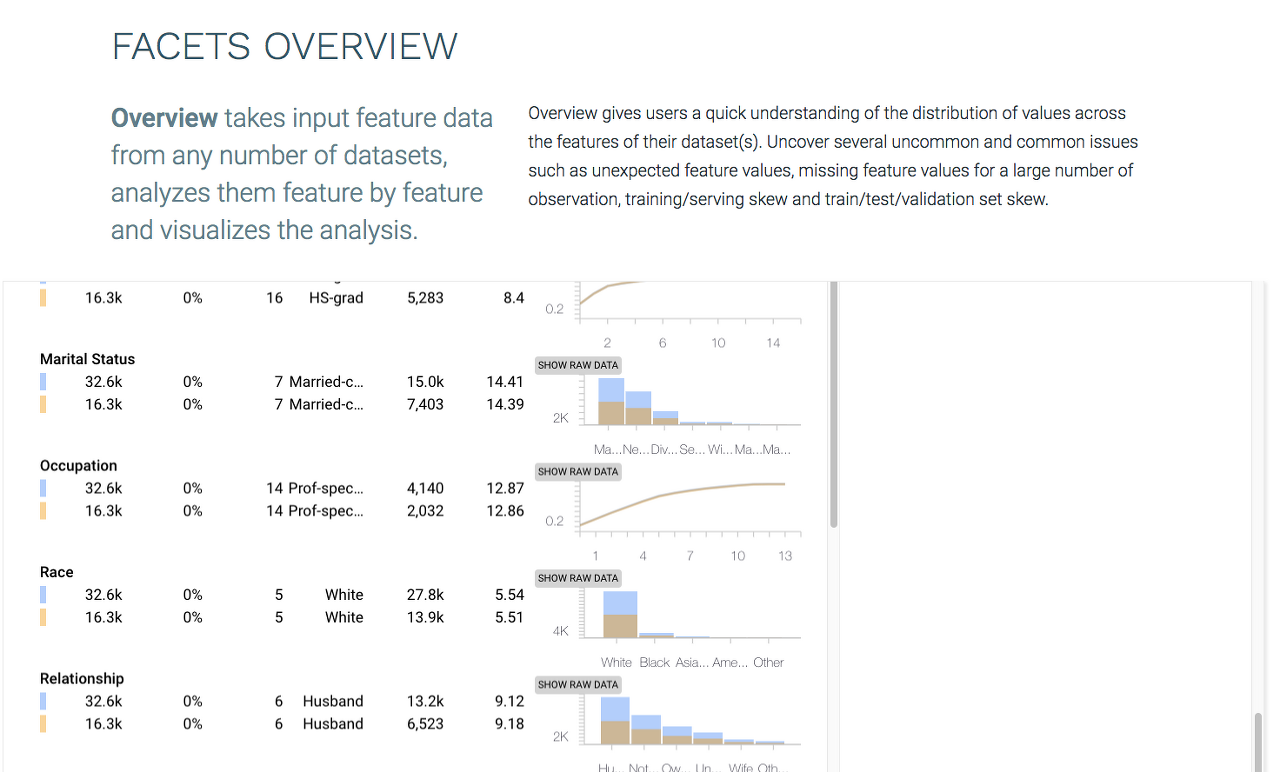
데이터의 컬럼을 손실 비율, 최대/최소값, 평균, 중간값, 표준편차 같은 통계같은 핵심적인 정보를 보여주는 열로 분리한다. 또한 대부분의 값이 0인 경우를 알 수 있게 하는 0인 값의 비율 또한 보여준다.

또한 여러분의 훈련/테스트 셋에서 데이터의 분포도 볼 수 있다. 이는 테스트 데이터가 훈련데이터셋과 유사한 분포를 갖는지 이중 점검하기 위한 좋은 방법이다.
So what?
적어도 스스로 이 수준의 분석을 하는 것이 기술적으로 최고의 사례지만 데이터의 모든 컬럼의 이러한 모든 면을 점검하는 것은 힘들다. 이 도구는 이 중요한 단계를 잊지 않도록 하고 비정상을 강조해 준다.
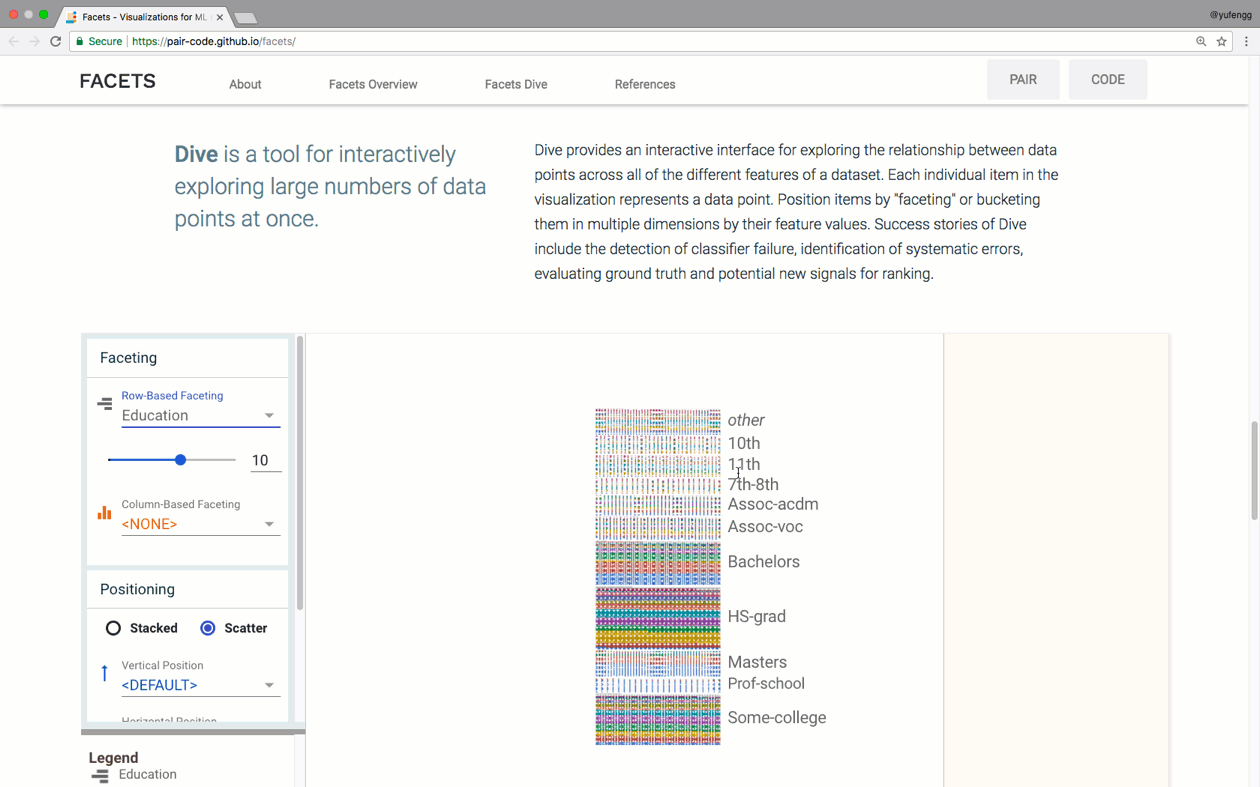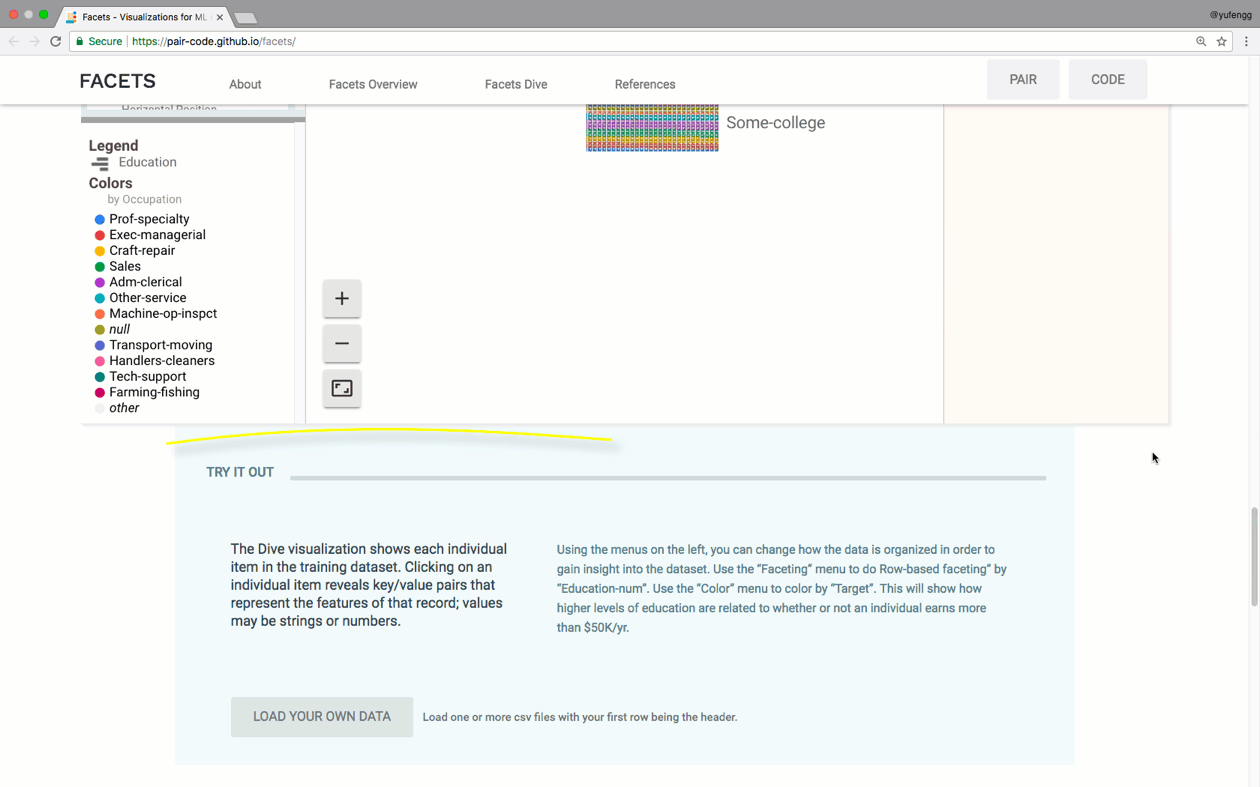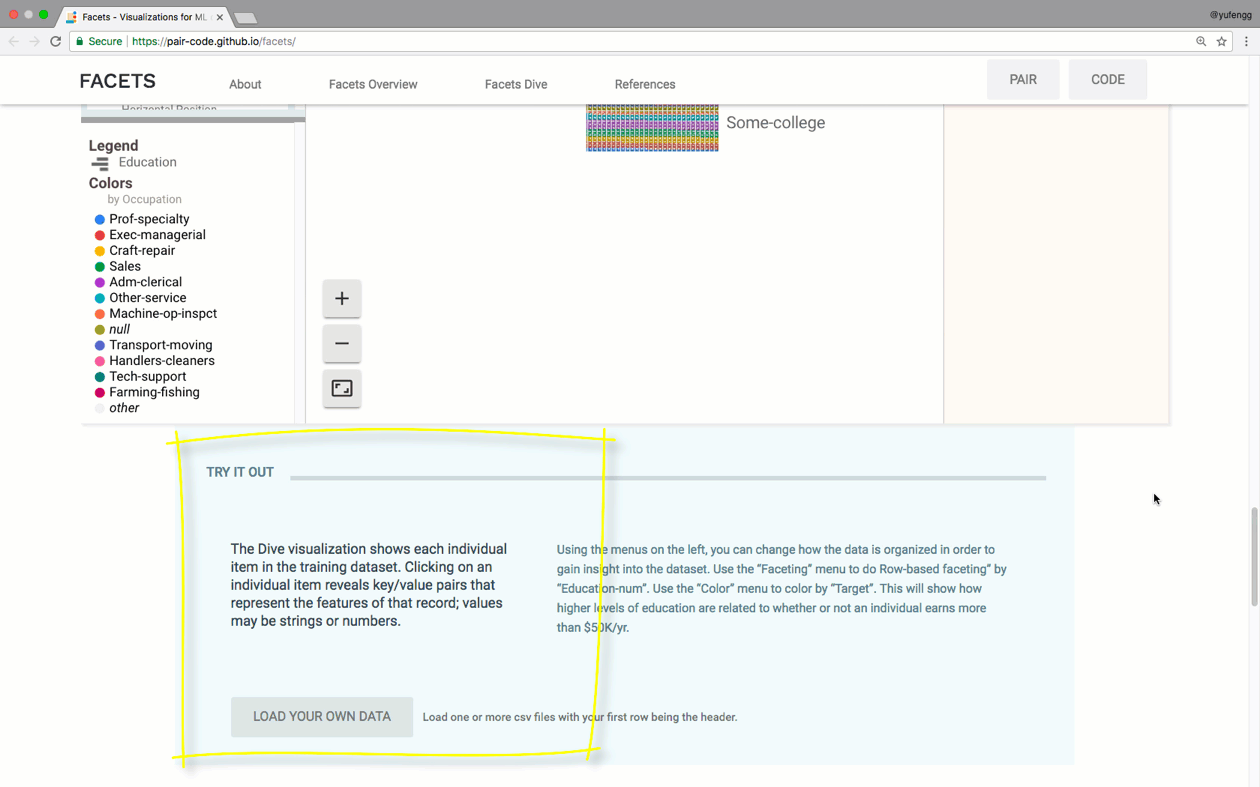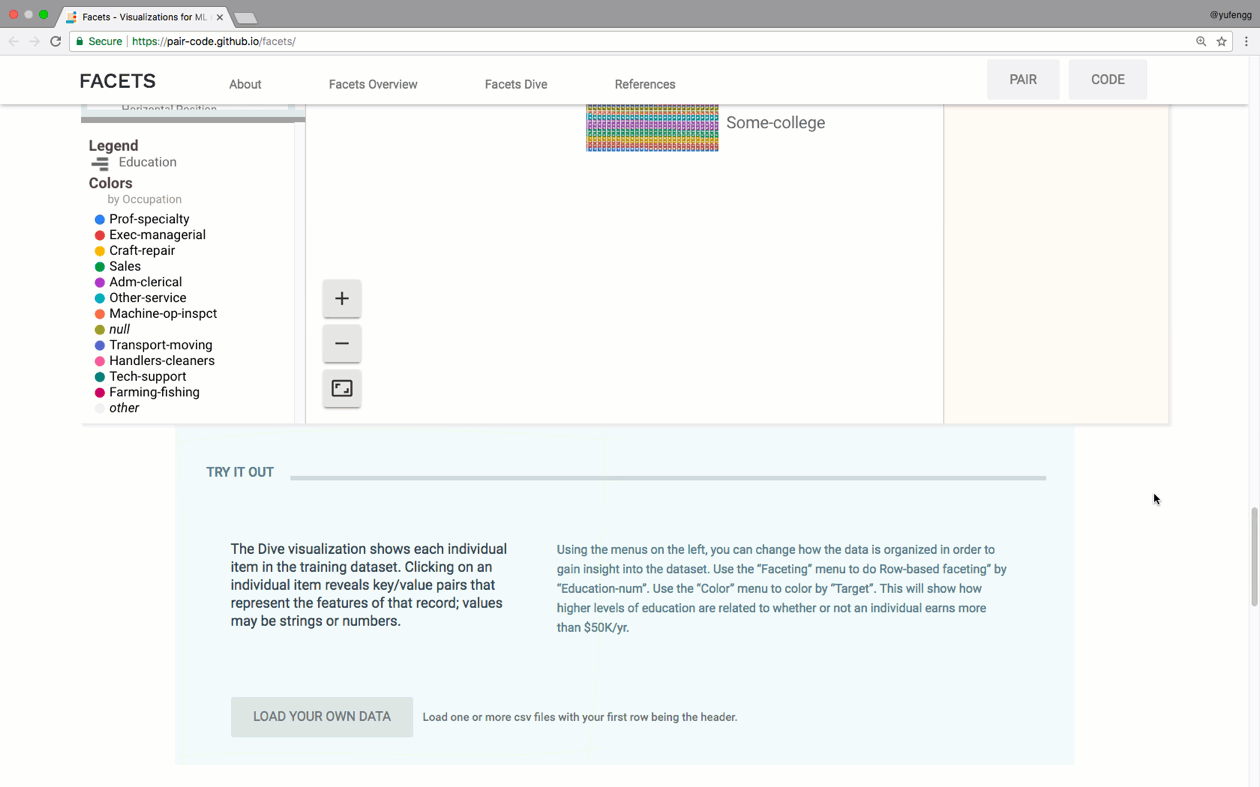
Facets Dive
이제 Facets Dive를 살펴보자. 이는 데이터셋을 좀 더 명확하게 하고 데이터 가각의 조각을 보기 위해 확대할 수 있게 한다.
여러분은 데이터셋의 어떠한 특성에 대해서도 열(row)과 행(column)으로 데이터를 'facets'할 수 있다. 이는 여러분이 신발을 온라인 쇼핑하는 것과 비슷하다. 즉 크기, 브랜드, 생상 같은 다른 범주로 필터(filter)한다. 좀 더 확실하게 하기 위해 예제를 보자.

인터페이스는 4개의 주요 구역으로 나뉜다. 중앙의 주요 영역은 데이터를 확대/축소할 수 있다. 왼쪽 패널에서 faceting, 위치, 색상을 제어하기 위한 드롭다운으로 데이터의 정렬형태를 바꿀 수 있다. 바로 아래는 중앙 디스틀레이에 대한 범례(legend)가 있다. 오른쪽 패널은 데이터의 특정 열(row)에 대한 상세 뷰이다. 특정 데이터 포인트의 상세를 보기 위해 중앙 시각화영역에서 열을 선택할 수 있다.
이제 이 모두가 어떻게 결합하는지 보자.
이를 위해서 1994 US Census by Barry Becker에서 추출된 데이터셋인 “Census dataset”를 사용한다. 이 데이터셋은 가정의 연간 수입이 다양한 인구조사 통계를 기반으로 $50K이상인지 이하인지를 예측하는 것이 목표이다.
Facet by Row
우선, 목표값(target value)를 기반으로 데이터포인트를 연령범위, 색상으로 분할한다. 여기서 파란색은 50K보다 작고 빨간색은 50K보다 더 큰것을 나타낸다.

Facet by Column
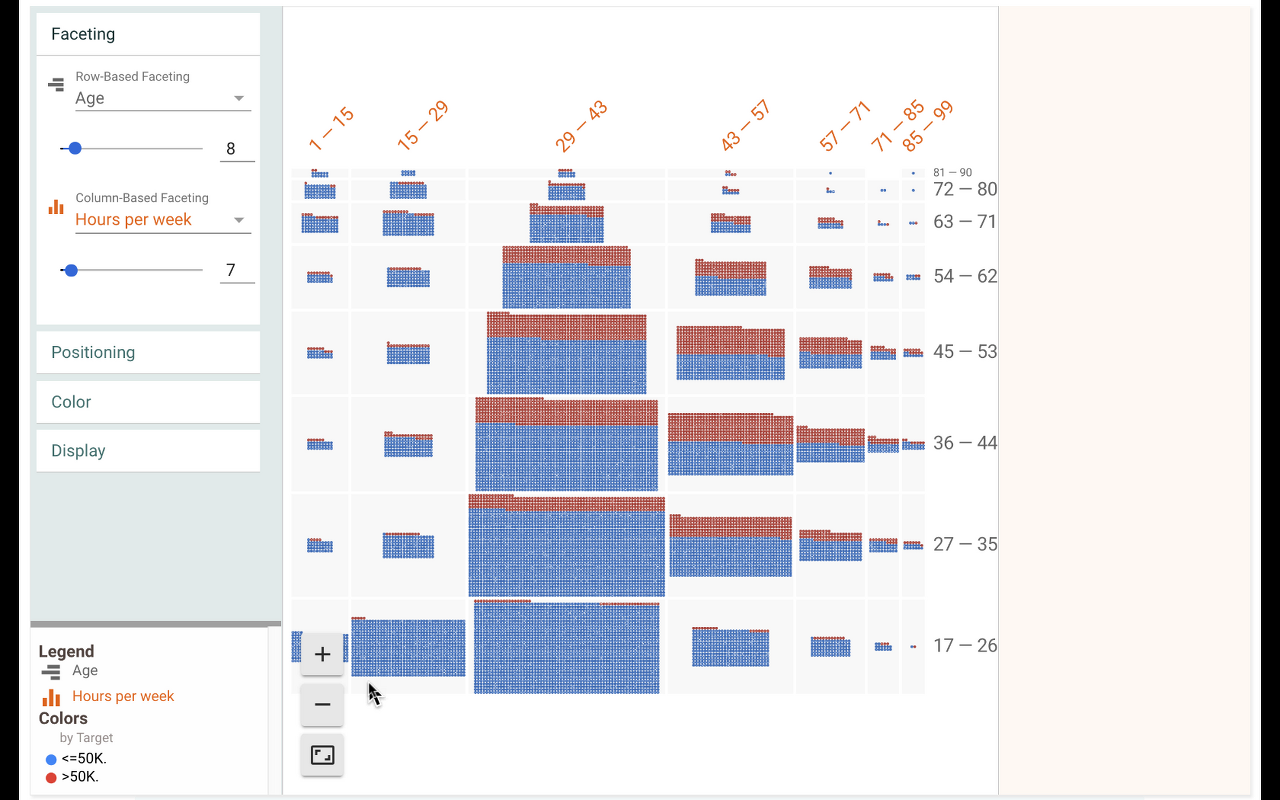
이제 나이로 데이터의 또다른 특성을 나누어 볼 수 있다. 주당 시간의 차이는 나이 범위에 걸쳐 다른 결과를 만드는가? 주당 시간으로 컬럼을 faceting하여 알아보자.

주당 15시간에서 29시간 일하는 17세에서 26세 연령대에 더 큰 그룹이 있다는 것을 안다. 이는 아마도 여름 아르바이트를 하는 아이들의 결과일 것이다. 또한 더 나이가 들면서 29시간에서 43시간 일하는 사람이 더 줄어드는 경향을 볼 수 있다. 반면, 43시간에서 57시간 부분은 차트의 중심에 상대적으로 일정하게 유지된다.
Positioning
그러나 여전히 우리가 찾는 것을 많이 보여주지 않는다. 그래프의 위치(positioning)를 변경하고 좀 더 상세한 것을 얻어보자. 여기서는 위치를 '산점도(scatter)'로 바꾸고 나이에 대해서남 facet한다. 또한 수직 정렬 순서로 "주당 시간(Hours per Week)"를 선택하여 다른 나이 그룹에 대한 근무 시간을 더 쉽게 알 수 있게 만든다. 이제 차트 중간에서 증가하고 양쪽 끝에서 낮아지는 주당 시간을 볼 수 있다.

테이터 탐색을 계속하여 찾을 수 있는 경향과 관계가 무엇인지 알아야 한다. 예를 들면, 국적으로 facet하면 데이터가 많이 치우친(skewed)것을 알 수 있다. 이는 좀 더 균형잡힌 데이터셋을 갖기 위해 더 많은 데이터 포인트를 수집할 수 있음을 말한다.
Load up your data
Facets에 데이터셋을 로드하는 방법을 알아보자. 이는 2가지 옵션이 있다.
웹 인터페이스를 사용하여 데이터를 직접 업로드하고 브라우져에서 사용하는 것과 project’s GitHub page의 설치를 사용하여 Jupyter notebook 확장으로 라이브러리를 설치할 수 있다.
Facets는 여러분의 데이터셋을 자세히 들여다보고 다른 특성간 관계를 찾고 데이터셋에 손실 또는 기대하지 않은 값이 없도록 하기 위해 유용한 도구이다.