Tensorflow.org의 링크 내용을 정리함.
텐서보드 Embedding projector를 사용한 데이터 시각화
TensorBoard Embedding Projector를 사용하여, 고차원 임베딩(embedding)을 도표로 표현한다. 이는 시각화, 검사 그리고 임베딩 레이어를 이해하는데 도움을 준다.

이 글에서는 어떻게 이런 형태의 훈련된 레이어를 시각화하는지 본다.
임베딩(Embedding)
: 범주형 데이터를 연속형 벡터로 변환하는 것. 주로 인공신경망 학습을 통해 범주형 자료를 벡터 형태로 바꾼다. 인공신경망 학습 과정을 통해 각 벡터에 가장 알맞는 값을 할당하게 된다. 이 과정에서 각 범주(category)는 각각의 특징을 가장 잘 표현할 수 있는 형태의 벡터값을 가지게 된다.
Setup
이 글에서는 영화평론 데이터셋을 분류하기 위해 생성된 임베딩 레이어를 시각화하기 위해 텐서보드를 사용하는 것을 배운다.
Source>>
import os
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorboard.plugins import projector
IMDB Data
IMDB에서 25,000개의 감정(긍정/부정)으로 레이블링된 영화 리뷰 데이터셋을 사용한다. 리뷰는 전처리되어 있고 각 리뷰는 단어 인덱스(integer)로 인코딩 되어 있다. 편의를 위해, 예를 들어 정수 '3'의 인스턴스가 데이터에서 3번째로 가장 빈도 높은 단어를 인코딩하도록 단어는 데이터셋내에서 전체적인 빈도에 의해 인덱스되었다. 이는 '오로지 가장 일반적인 상위 10,000단어만 고려하지만, 가장 많은 20개 단어는 제거한다'같은 빠른 필터링을 가능하게 한다.
관습적으로 '0'은 특정 단어를 나타내지 않고, 대신 어떤 알수없는(unknown) 단어를 인코딩한다. 이 글 후반부에서는 시각화에서 이 열(row)을 제거한다.
Soruce>> 다운로드 오류 발생시, pip install ipywidgets 수행
(train_data, test_data), info = tfds.load(
"imdb_reviews/subwords8k",
split=(tfds.Split.TRAIN, tfds.Split.TEST),
with_info=True,
as_supervised=True,
)
encoder = info.features["text"].encoder
# shuffle and pad the data.
train_batches = train_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
test_batches = test_data.shuffle(1000).padded_batch(
10, padded_shapes=((None,), ())
)
train_batch, train_labels = next(iter(train_batches))
Keras Embedding Layer
케라스 임베딩 레이어는 어휘에서 각 단어에 대한 임베딩을 훈련하는데 사용할 수 있다. 각 단어는 모델에 의해 훈련되는 16차원 벡터(또는 임베딩)과 관련된다.
단어 임베딩에 대한 더 자세한 부분은 여기를 보자.
Source>>
# Create an embedding layer
embedding_dim = 16
embedding = tf.keras.layers.Embedding(encoder.vocab_size, embedding_dim)
# Train this embedding as part of a keras model
model = tf.keras.Sequential(
[
embedding, # The embedding layer should be the first layer in a model.
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(1),
]
)
# Compile model
model.compile(
optimizer="adam",
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=["accuracy"],
)
# Train model
history = model.fit(
train_batches, epochs=1, validation_data=test_batches, validation_steps=20
)
2500/2500 [==============================] - 10s 4ms/step - loss: 0.5256 - accuracy: 0.6755 - val_loss: 0.3886 - val_accuracy: 0.8300
텐서보드용 데이터 저장
텐서보드는 지정된 log_dir 디렉토리의 로그에서 텐서플로 프로젝트의 메테데이터와 텐서를 읽는다. 이 글에서는 로그 디렉토리로 'logs/imdb-example/'을 사용한다.
데이터를 시각화하기 위해, 사각화를 위한 레이어를 이해하기 위한 메타데이터도 함께 로그 디렉토리에 checkpoint를 저장한다.
Source>>
# Set up a logs directory, so Tensorboard knows where to look for files
log_dir='/logs/imdb-example/'
if not os.path.exists(log_dir):
os.makedirs(log_dir)
# Save Labels separately on a line-by-line manner.
with open(os.path.join(log_dir, 'metadata.tsv'), "w", encoding='utf-8') as f:
for subwords in encoder.subwords:
f.write("{}\n".format(subwords))
# Fill in the rest of the labels with "unknown"
for unknown in range(1, encoder.vocab_size - len(encoder.subwords)):
f.write("unknown #{}\n".format(unknown))
# Save the weights we want to analyse as a variable. Note that the first
# value represents any unknown word, which is not in the metadata, so
# we will remove that value.
weights = tf.Variable(model.layers[0].get_weights()[0][1:])
# Create a checkpoint from embedding, the filename and key are
# name of the tensor.
checkpoint = tf.train.Checkpoint(embedding=weights)
checkpoint.save(os.path.join(log_dir, "embedding.ckpt"))
# Set up config
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
# The name of the tensor will be suffixed by `/.ATTRIBUTES/VARIABLE_VALUE`
embedding.tensor_name = "embedding/.ATTRIBUTES/VARIABLE_VALUE"
embedding.metadata_path = 'metadata.tsv'
projector.visualize_embeddings(log_dir, config)
Console>>
> tensorboard --logdir=logs/imdb-example/

분석
TensorBoard Projector는 데이터를 분석하고 서로 관련있는 임베딩 값을 보기 위한 훌륭한 도구이다. 대쉬보드는 특정 용어를 검색하고 임베딩 공간에서 근처에 있는 단어를 하이라이트 한다. 이번 예제에서 Wes Anderson과 Alfred Hitchcock 두 단어 모두 꽤 중립적인 단어지만, 다른 컨텍스트에서 참조되고 있다는 것을 볼 수 있다.

Hitchcock은 nightmare 같은 단어와 연관성이 있어 보인다.. 이는 공포 영화인 그의 직업에 연관되었을 수 있다. 반면, Anderson은 그의 가슴따뜻하게 하는 스타일을 반영하여 heart 단어와 연관성을 보여준다.

실제 실행 결과는 좀 다르게 나왔다. 아마도 원문 작성 시기의 차이 때문에 imdb 데이터셋이 변화가 있어 그렇지 않을까 예상한다.
nightmare 조회

확대 및 각도 조절해서 보면, wars, angel 등의 연관성을 확인할 수 있다.
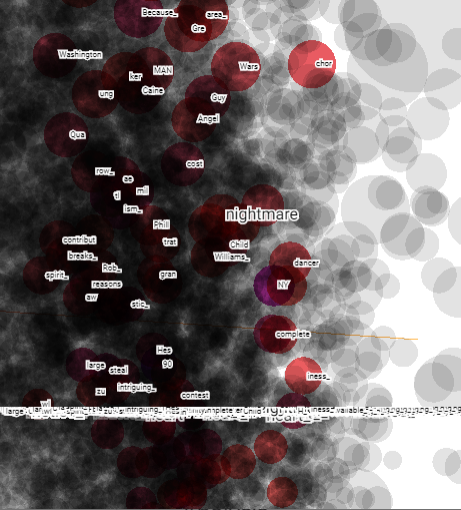
heart 조회

Anderson 조회 : kids 등의 연관성을 확인할 수 있다.
