A field guide to the most popular parameters
이 글에서는 통계에ㅔ서 가장 유명한 파라미터에 대해 다루어본다.
Mean(평균)
평규(average)이다.
Expected value(기대값)
$E(X)$ 또는 $E(X=x)$로 나타내는 기대값은 확률변수(random variable) X에 대해 이론적 확률 가중치가 적용된 평균(mean)이다.
기대값에 해당하는 확률 $P(X = x)$로 X가 갖을 수 있는 각 잠재적인 값(potential value) x를 가중(weighting, multiplying)하고 이를 조합하여 구할 수 있다.(키같은 연속값은 적분으로 센티미터로 반올림된 키같은 이산값은 합하여 조합한다.): $E(X) = \sum{xP(X=x)}$
균일한 6면 주사위라면 X는 동일 확률 1/6으로 {1, 2, 3, 4, 5, 6}에서 각 값을 취할 수 있다. 따라서,
$E(X) = (1)(1/6) + (2)(1/6) + (3)(1/6) + (4)(1/6) + (5)(1/6) + (6)(1/6) = 3.5$
즉, 3.5가 X에 대한 확률 가중치가 적용된평균이고 아무도 3.5가 주사위의 결과가 될 수 없다는 것에 신경쓰지 않는다.
Variance(분산)
모멘트(moment)를 설명해야하기 때문에 위에서 본 E(x) 수식에서 X를 $(X - E(X))^2$교체하는 것은 무엇인가 매우 유욯함을 제공한다.
$V(x) = E[(X - E(X))^2] = \sum{[x - E(X)]^2P(X = x)} = E[(X)^2] - [E(X)]^2$
주사위 굴리기에 대한 분산을 얻기위한 식은 다음과 같다.
$V(X) = \sum{[x-E(X)]^2P(X=x)} = \sum{(x-3.5)^2P(X=x)} = (1-3.5)^2(1/6) + (2-3.5)^2(1/6) + (3-3.5)^2(1/6) + (4-3.5)^2(1/6) + (5-3.5)^2(1/6) + (6-3.5)^2(1/6) = 2.91666...$
Moment(모멘트)
모멘트는 기대값의 특별한 종류로 다음과 같은 패턴이 있다.
1st raw moment: E[(X)] ……… 1st central moment: E[(X — 𝜇)]
2nd raw moment: E[(X)²] ……. 2nd central moment: E[(X — 𝜇)²]
3rd raw moment: E[(X)³] …..… 3rd central moment: E[(X — 𝜇)³]
…………………………..and so on…………………………………
모멘트가 분포의 모양에 대해 알려주기 때문에 알만한 가치가 있다. 3rd central moment를 확장하는 것은 분포의 왜도(skewness)를 제공하고 4rd central moment를 확장하는 것은 분포의 첨도(kurtosis)("tailedness")를 제공한다.
Tails(꼬리)
"Tailedness"는 통계학에서 많이 나오는 단어이다.
image :SOURCE
이것에 "tails"라고 이름지은 누군가는 아마도 분포가 꼬리를 가진 생물처럼 생겼다고 생각했을 것이다.
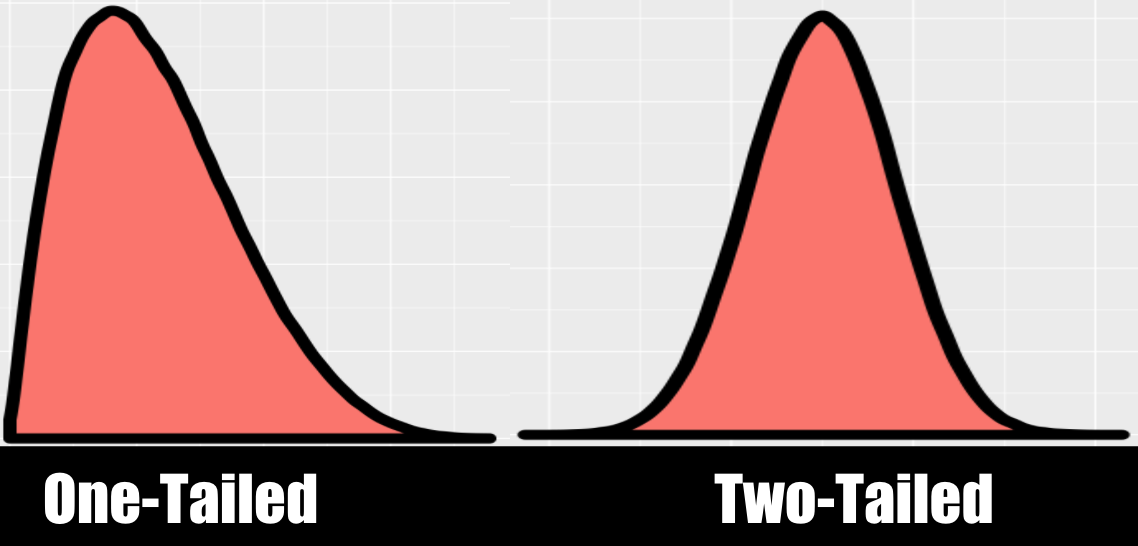
Kurtosis(첨도)
첨도는 꼬리(tail)의 통통함을 설명하는 방법이다. 여러분이 첨도를 자주 나타내지 않을 가능성이 있다. 그러니 이에 대해 외우지 말고 필요할때 찾아보자.
Here, I made you a guide to kurtosis (tailedness). Okay, this might be a better guide.
Skewness(왜도)
어떤것이 있고, 어떤때 좌로 치우친(left-skewed), 우로 치우친(right-skewed), 양으로 치우친(positive-skewed), 음으로 치우친(negative-skewed) 분포가 되는지는 여러분이 그 답이 꼬리가 향하는 방ㅎ양에 있다는 것을 알때까지는 기억하기 힘들다. 이를 아래 공룡사진으로 알아보자.
Wherever that “tail” is pointing, that’s your answer. Image: SOURCE.
위 공룡사진은 꼬리가 향하는 방향때문에 좌로 치우친(또는 음으로 치우친) 분포가 될 것이다.
Moment Generating Functions
여러분이 충분한 모멘트를 얻지 못한다면 MGFs(Moment Generating Functions)이 있다. MGFs가 훌륭한 것은 MGFs가 고유하게 분포를 결정(따라서 CDFs와 PDFs 대신 사용할 수 있다.) 한하고 여러분이 희망하는 모든 모멘트를 계산하는 빠른 방법을 제공한다는 점이다.
여러분이 주로 가장 유명한 모멘트로 작업하기 때문에 필요없을 수 도 있다.
First raw moment = 𝜇 = E[(X)]
Second central moment = 𝜎² = E[(X — 𝜇)²]
익숙해 보이는가? 맞다 평균과 분산이다.
Variance, again
분산은 확률변수가 평균에서 얼마나 많이 다른가를 나타낸다.
평균은 그 자체로 얼마나 작은지를 나타낸다는 것을 염두해 두자. 예를 들면, 하루는 4시간, 다른 하루는 12시간인 수면시간에 대한 평균 수면시간을 본다면 동일한 평균임에도 불구하고 8과 8은 동일하지 않다.
분산이 낮을 수록 예측을 하는것이 더 쉽다.
분산은 확률이 될 때 매우 중요한 개념이다. 왜냐하면 분산이 낮을 수록 예측하기 더 쉽기 때문이다. 분산이 없을 때 여러분은 확실하게 대답한다.
분산이 이런 종류의 정보를 전달하기 위해 가장 표현가능한 방법은 아니기 때문에 결과를 퍼트리기 전에 제곱근을 취한다.
Standard deviation(표준편차)
표준편차는 분산의 제곱근이다. ($\sigma^2$ 대신 $\sigma$이다.) 따라서 동일한 것을 측정한다. 분산대신 표준편차로 결과를 보고하는 것이 더 친숙하다.
학교에서 여러분은 표준편차가 평균 주위에 값의 평균 퍼짐을 알려준다고 배웠다.
MAD (평균절대편차)
평균절대편차는 "평균주변에 값에 대한 평균 퍼짐(산포)"을 이야기할 때 직관적으로 상상하는 것이다.
불행히도 평균절대편차의 식은 작업하는데 절재적으로 해로울 수 있다. 절대값 함수(마이너스 부호를 없애는)는 몇몇 최적화 기술 MAD를 만드는 날카로운 코너를 동반한다. 따라서 종종 충분히 가까운 표준편차로 작업하는 것을 선호한다.)
Median(중앙값)
중앙값은 "중심의 것"을 나타낸다. 중앙값은 보통 "평균 수입"을 이야기할 때 여러분이 생각하고 싶은 양이다. 한 그룹이 {1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 100000000000}의 급여라면 중앙값은 평균 급여보다 그 그룹에서 어떤일이 일어나고 있는지에 대한 더 유용한 요약을 제공한다. 여러분은 이 분포가 one-tailed이고 오른쪽으로 치우친 것을 눈치챌 수 있다.
Mode(최빈값)
최빈값은 "가장 일반적인 값"이다. 최빈값은 분포/히스토그램의 정점과 일치한다. 분포가 multimodal이라고 하면 이는 하나이상의 정점(peak)이 있다는 의미이다. 분포가 symmetric(대칭) and unimodal(단봉)이라고 하면 종모양 곡선같다는 의미이다. 최빈값은 또한 평균일 수 있다.
Why mean and variance?
사람들이 좀 더 직관적으로 중앙값과 MADs를 생각한다면 왜 학생들은 평균과 분산에 대해 배울까? 그것은 평균과 분산함수가 다양한 수학적 기법을 수행하기 위해 좀 더 편리하기 때문이다.