Tensorflow.org의 링크 내용을 정리함.
텐서보드(TensorBoard)로 시작하기
ML에서, 무엇인가 개선하기 위해 때때로 측정할 수 있어야 한다. 텐서보드는 ML 작업흐름(workflow) 동안 필요한 측정과 시각화를 제공하기 위한 도구이다. 이것은 손실과 정확도 같은 실험 지표 추적, 모델 그래프 시각화, 더 낮은 차원으로 embedding 투영 등을 가능하게 한다.
이 글에서는 텐서보드를 빠르게 시작할 수 잇는 방법을 보여주지만, 구체적인 내용은 다른 글에서 다룬다.
(※ 이 글은 원문과는 다르게 Windows10, Anaconda에서 spyder를 이용하였다.)
참고로 원문에서는
# Load the TensorBoard notebook extension %load_ext tensorboard %tensorboard --logdir logs/fit위와 같이 %로 시작하는 명령으로 수행하는 경우,
Spyder에서 해당 소스의 리소스를 release하지 않는 듯한 현상이 발생하였다.
(새로운 데이터 소스 적용시 갱신이 안되는 현상)
우선 필요한 패키지를 import한다.
import tensorflow as tf
import datetime
Import os 데이터셋은 MNIST 데이터셋을 사용한다.
데이터를 정규화하고 10개 분류를 위한 케라스 모델을 생성한다.
정규화(Normalization) = $\frac{x - min}{max - min}$
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28, 28)))
model.add(tf.keras.layers.Dense(512, activation='relu'))
model.add(tf.keras.layers.Dropout(0.2))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])Keras Model.fit()으로 TensorBoard 사용하기
Keras의 Model.fit()으로 훈련을 진행할 때, **tf.keras.callbacks.TensorBoard callback**을 추가하면 log가 생성되고 저장된다. 또한 **histogram freq=1** (이 인자의 기본값은 off이다.)로 매 epoch마다 히스토그램 계산을 가능하게 한다.
여러 훈련 수행에 대해 쉬운 로그 선택을 위해 시간으로 표시되는 디렉토리에 로그가 기록되도록 하자. log_dir = os.path.join("logs", "fit",
datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir,
histogram_freq=1, profile_batch=100000000)
model.fit(x=x_train,
y=y_train,
epochs=5,
validation_data=(x_test, y_test),
callbacks=[tensorboard_callback]) 여기서 **profile\_batch=100000000** 인자는ProfilerNotRunningError: Cannot stop profiling. No profiler is running.
위의 오류가 발생할 경우, 추가한다.
아나콘다의 Command prompt에서 사용 중인 가상환경을 활성화 한 후, 텐서보드를 실행한다. > activate VENV_NAME
> tensorboard --logdir=logs/fit현재 tensorboard를 실행 시키는 디렉토리의 하위 디렉토리로 logs/fit 디렉토리가 존재해야 한다. 만약, 로그 디렉토리의 경로가 다르다면, 전체 경로를 사용해도 된다.

대쉬보드의 메뉴바에 나타는 것은 다음과 같다.SCALARS
: Epoch마다 손실(loss)와 지표(metrics)가 얼마나 변하는지 보여준다. 이것은 훈련 속도, 학습률 그리고 다른 스칼라(scalar) 값을 추적하기 위해 사용할 수도 있다.
GRAPHS
: 모델을 시각화한다. 위 예제의 경우, 모델이 바르게 만들어졌는지 확인할 수 있는 케라스 그레프 레이어가 보인다.
DISTRIBUTIONS / HISTOGRAMS
: 시간에 따른 텐서(Tensor)의 분포를 보여준다. 이것은 가중치(Weight)와 편향(bias)의 시각화에 유용하고 이것들이 예상한 방향으로 변화하는지 확인할 수 있게 한다.
텐서보드 플러그인은 자동적으로 데이터의 다른 타입을 로그로 만기면 활성화 된다. 예를 들면, Keras TensorBoard callback은 image와 embedding 또한 로그로 남길 수 있게 한다. 우측 상단의 inactive를 드롭다운하면, 텐서보드에서 사용가능한 다른 플러그인을 확인할 수 있다.
다른 방법으로 TensorBoard 사용하기
tf.GradientTape()과 같은 방법으로 모델을 훈련할 때, 필요한 정보를 로그로 남기기 위해서는 tf.summary를 사용한다.
위와 동일하게 MNIST 데이터셋을 사용하지만, 배치의 이점을 얻기 위해 이를 tf.data.Dataset으로 변환한다. train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
train_dataset = train_dataset.shuffle(60000).batch(64)
test_dataset = test_dataset.batch(64) 손실함수(loss function)와 옵티마이져(Optimizer)를 선택한다. loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
optimizer = tf.keras.optimizers.Adam() logits - 관련쓰레드
softmax에 입력으로 사용되어지는 값.
Logits은 확률 [0, 1]을 R[-int, inf]로 매핑하기 위해 사용된다.
$L = \ln \left({p \over 1-p} \right) \Rightarrow p={1 \over 1+e^{-L} }$
- logit 0은 0.5 확률과 일치한다.
- 음수 logit은 0.5보다 작은 확률과 일치한다.
- 양수 logit은 0.5보다 큰 확률과 일치한다.
ML에서 logit은 분류 모델이 생성하는 raw 예측의 벡터로써 정의되어 질 수 있고 이것은 정규화 함수로 전달된다. 이런 경우, 모델은 여러 분류를 갖는 분류 문제를 해결하고 logit은 softmax 함수에 입력으로써 동작할 것이다. 그러면, softmax 함수는 각 분류에 대한 하나의 값을 갖는 확률의 벡터를 생성한다. Logit은 때때로 sigmoid 함수의 요소별 역함수로 표현하기도 한다.
훈련이 진행되는 동안의 값을 축적할 때 사용할 지표(metrics)를 생성한다. # Define our metrics
train_loss = tf.keras.metrics.Mean('train_loss', dtype=tf.float32)
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy('train_accuracy')
test_loss = tf.keras.metrics.Mean('test_loss', dtype=tf.float32)
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy('test_accuracy') tf.keras.metrics.Mean(
**name='mean', dtype=None**)
주어진 값의 (가중치) 평균을 계산한다.
Args
- name : (Optional) 지표(metric) 인스턴스(instance)의 이름(String)
- dtype : (Optional) 지표 결과의 data type
훈련 및 테스트를 위한 함수를 정의한다. def train_step(model, optimizer, x_train, y_train):
with tf.GradientTape() as tape:
predictions = model(x_train, training=True)
loss = loss_object(y_train, predictions)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
train_loss(loss)
train_accuracy(y_train, predictions)
def test_step(model, x_test, y_test):
predictions = model(x_test)
loss = loss_object(y_test, predictions)
test_loss(loss)
test_accuracy(y_test, predictions)다른 로그 디렉토리에 Summary를 기록하기 위해 summary writer를 설정한다. current_time = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
train_log_dir = 'logs/gradient_tape/' + current_time + '/train'
test_log_dir = 'logs/gradient_tape/' + current_time + '/test'
train_summary_writer = tf.summary.create_file_writer(train_log_dir)
test_summary_writer = tf.summary.create_file_writer(test_log_dir) 훈련 및 테스트를 수행한다. model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28, 28)))
model.add(tf.keras.layers.Dense(512, activation='relu'))
model.add(tf.keras.layers.Dropout(0.2))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
EPOCHS = 5
for epoch in range(EPOCHS):
for (x_train, y_train) in train_dataset:
train_step(model, optimizer, x_train, y_train)
with train_summary_writer.as_default():
if not tf.summary.scalar('loss', train_loss.result(), step=epoch):
print("train_loss summary failed")
if not tf.summary.scalar('accuracy', train_accuracy.result(), step=epoch):
print("train_acc summary failed")
for (x_test, y_test) in test_dataset:
test_step(model, x_test, y_test)
with test_summary_writer.as_default():
if not tf.summary.scalar('loss', test_loss.result(), step=epoch):
print("test_loss summary failed")
if not tf.summary.scalar('accuracy', test_accuracy.result(), step=epoch):
print("test_acc summary failed")
template = 'Epoch {}, Loss: {}, Accuracy: {}, Test Loss: {}, Test Accuracy: {}'
print (template.format(epoch+1,
train_loss.result(),
train_accuracy.result()*100,
test_loss.result(),
test_accuracy.result()*100))
# Reset metrics every epoch
train_loss.reset_states()
test_loss.reset_states()
train_accuracy.reset_states()
test_accuracy.reset_states() Epoch 1, Loss: 0.24321186542510986, Accuracy: 92.84333801269531, Test Loss: 0.13006582856178284, Test Accuracy: 95.9000015258789
Epoch 2, Loss: 0.10446818172931671, Accuracy: 96.84833526611328, Test Loss: 0.08867532759904861, Test Accuracy: 97.1199951171875
Epoch 3, Loss: 0.07096975296735764, Accuracy: 97.80166625976562, Test Loss: 0.07875105738639832, Test Accuracy: 97.48999786376953
Epoch 4, Loss: 0.05380449816584587, Accuracy: 98.34166717529297, Test Loss: 0.07712937891483307, Test Accuracy: 97.56999969482422
Epoch 5, Loss: 0.041443776339292526, Accuracy: 98.71833038330078, Test Loss: 0.07514958828687668, Test Accuracy: 97.5훈련 모니터링을 위해 텐서보드를 새로 기록된 로그 디렉토리로 열자 > tensorboard –logdir=logs/radient_tape 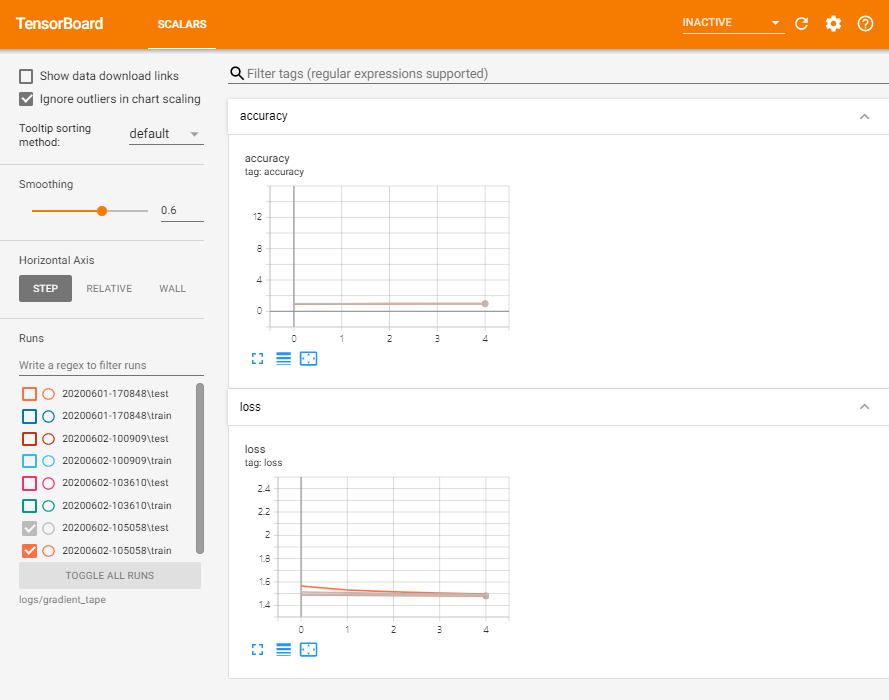
티스토리는 마크다운 수식을 지원 안하는 듯 싶다.. 수식이 깨지네...